excel公式技巧:从单元格区域的字符串中提取唯一值
如下图1所示,单元格区域A1:A10中有一些数据。现在,您想要从这个区域提取单词并创建一个唯一的值列表,如b列中的数据所示。

图1
您可以在单元格B1中编写一个公式,并将其向下拖动以创建唯一值列表。这个公式怎么写?
先不看答案,自己试试。
公式
在单元格B1中输入数组公式:
=IF(ROWS($1:1)$C$1,"",INDEX(Arry3,SMALL(IF(FREQUENCY)(IF(Arry3 " "),MATCH(Arry3,arry 3,0)),Arry2),Arry2),ROWS($1:1)))
向下拉,直到出现一个空单元格。
在单元格C1中,使用以下数组公式:
=sum((Arry3 " ")/mmult(0(arr y3=转置(arr y3)),ROW(间接(“1:”counta(arry3)))^0))
计算单元格区域A1:A10中不重复的单个单词数。
公式分析
在公式中,Arry1、Arry2和Arry3是定义的三个名称。
名称:Arry1。
参考位置:=1 len(数据)-len(替换(数据,"," "))。
名称:Arry2。
参考位置:=行(间接(“1:”(最大值(arry1) *行(数据)))。
名称:Arry3。
参考位置:=索引(trim (mid(替代(data)、"、replt("、999))、转置(999 * (row(间接)(" 1:" max (arry1)))-1)、999))。
在上面的名称中,使用了另一个定义的名称:数据。
参考位置:=Sheet1!1:澳元10澳元
1.我们先来看一个名字Arry3,它是我们公式的关键部分。名称Arry3的定义公式:
=INDEX(TRIM(MID(replace(Data),"," REPT(",999)))、TRANSPOSE(999 *(ROW(INDIRECT)(" 1: " MAX(arr y1)))-1)1)、999))、N(IF(1,1 INT((Arry2-1)/MAX(Arry1)))))
(1)使用TRIM、MID、replace和REPT功能的结构是标准的(并且非常有用的)组合。给定由特定字符(空格、逗号、分号等)分隔的字符串。),该构造可以用来提取这些分离的子串中的任何一个,或者(像这个例子一样)生成一个由这些分离的子串组成的数组,以便按照我们想要的方式进行操作。
现在,只需将上述公式应用于数据中的第一个单元格,就能理解它的工作原理。我们还会用SUMPRODUCT封装这个结构,不是因为我们真的想对“苋菜”、“青铜”和“白银”求和,而是因为我们可以强制返回一个数组。因此,我们将使用的公式是:
=SUMPRODUCT(TRIM(MID(replace(A1),"," REPT(",",99))),99 *(ROW(INDIRECT(" 1: " 1 LEN(A1)-LEN(replace(A1,",","))))))-1) 1,99)))
(为了方便解释,这里把上面的999简化为99。)
这个公式构造的关键点是字符串中所有空格的初始替换,基本上使用了更多的空格。如果使用的字符串由逗号或分号分隔,情况将是一样的:我们将用更多的空格替换所有的逗号或分号。
这里,生成具有更多空格的字符串的部分是Rept(",99 "),它构成了具有99个空格的字符串。
用空格替换后的公式为:
=SUMPRODUCT(TRIM(MID("苋菜青铜银,99 *(ROW(INDIRECT(" 1: " 1 LEN(A1)-LEN(replace(A1," "," ")))))-1) 1,99)))
此时,单词之间已经放置了大量空格。
查看MID函数中的参数start_num:
99 *(ROW(INDIRECT(" 1: " 1 LEN(A1)-LEN(replace(A1," "," "))))))-1) 1
单元格A1中的字符串长度为22,去掉单词之间的空格后的长度为20。因此:
1 LEN(A1)-LEN(代入(A1,"",""))
结果是:1 22-20,也就是3。
注意这个公式构造,可以有效计算出一个字符串中的子字符串个数(用空格隔开)。
这样,MID函数的参数start_num部分转换为:
99 *(ROW(INternet(" 1: " 3))-1)1
那就是:
99*({0;1;2}) 1
结果是:
{1;100;199}
这样,可以确保该示例中的所有拆分单词都在空格分隔的区域中。其实只要字数不长,我们选择的99这样的数字足够大,就能保证有效拆分字数。
事实上,可以保证有效获得分离区域的数值长度应该总是大于字符串中任何单个单词的长度。这样,我们可以选择这个值作为字符串的长度,因为单个子字符串的长度不能大于整个字符串本身的长度。因此,建议在这类公式结构中使用LEN(A1)来代替99甚至999。在本例中,由于公式将应用于一系列单元格,因此不使用此方法,但该值直接为999。
这里MID函数的第三个参数是99,这样可以保证我们得到的子串中可以包含这个词。
这样,上面的SUMPRODUCT公式就变成了:
=SUMPRODUCT(TRIM(MID)(“苋菜青铜银”,{ 1;100;199},99)))
转换为:
=SUMPRODUCT(TRIM({“苋菜”;“青铜”;“银”}))
TRIM函数删除字符串前后的空格:
=SUMPRODUCT({“苋菜”;“青铜”;“银”})
好吧。原理很清楚,现在回到名称Arry3:
=INDEX(TRIM(MID(replace(Data),"," REPT(",999)))、TRANSPOSE(999 *(ROW(INDIRECT)(" 1: " MAX(arr y1)))-1)1)、999))、N(IF(1,1 INT((Arry2-1)/MAX(Arry1)))))
请记住,我们没有将单个单元格传递给TRIM(MID(replace),而是传递了一个单元格区域。首先看公式中MID函数指定起始位置的参数部分:
转置(999*(行(间接)(“1:”最大值(arr y1))-1)1)
首先看看定义Arry1的名称:
1 LEN(数据)-LEN(替代(数据,“”、“”)
转换为:
1 LEN({“苋菜铜银”;“青铜”;"";《紫铜紫红》;“红色”;“紫褐色”;“灰褐色赭石青铜色”;“银红铈橙”;"";“Cerise”})-LEN(替补({“苋菜青铜银”;“青铜”;"";《紫铜紫红》;“红色”;“紫褐色”;“灰褐色赭石青铜色”;“银红铈橙”;"";“Cerise”}、“”、“”))
转换为:
1 {22;6;0;22;3;11;25;24;0;6}-{20;6;0;20;3;10;22;21;0;6}
结果是:
{3;1;1;3;1;2;4;4;1;1}
即单元格区域“数据”中每个单元格的单个单词数,除了第三行和第九行为空但仍返回不正确的数字1。但是因为我们只想得到构造数组的最大值,这些不正确的结果不会影响我们。
这样,MID函数指定起始位置的参数部分被转换为:
转置(999*(ROW)(间接(“1:”MAX({ 3;1;1;3;1;2;4;4;1;1})))-1) 1)
转换为:
转置({ 1;1000;1999;2998})
结果是:
{1,1000,1999,2998}
此时,部分公式转换为:
TRIM(MID(替代品(数据),"," REPT(",999)),{1,1000,1999,2998},999))
转换为:
TRIM({“苋菜”、“青铜”、“白银”、“士”;“青铜”、“”、“”、“”;"","","","";“紫罗兰”、“青铜”、“苋菜”、“;“红”、“”、“”、“”;“深褐色”、“青铜色”、“褐色”、“褐色”;“灰褐色”、“赭色”、“青铜色”、“瑟色”;“银色”、“红色”、“瑟色”、“橙色”;"","","","";“Cerise”、“”、“”、“”})
这是一个10行4列的数组。
下图显示了MID功能运行的结果。

图2。
TRIM函数使上面的数组变成:
{“苋菜”、“青铜”、“白银”、“士”;“青铜”、“”、“”、“”;"","","","";“紫罗兰”、“青铜”、“苋菜”、“;“红”、“”、“”、“”;“深褐色”、“青铜色”、“褐色”、“褐色”;“灰褐色”、“赭色”、“青铜色”、“瑟色”;“银色”、“红色”、“瑟色”、“橙色”;"","","","";“Cerise”、“”、“”、“”
现在,我们已经在单元格区域Data中创建了一个由所有单个子字符串(或单词)组成的数组,然后我们可以开始考虑处理数组中的元素以满足我们的要求。
(2)接下来,考虑从数组创建一个唯一值列表。我们有一些从列表中创建唯一值的标准公式,如下图3所示。
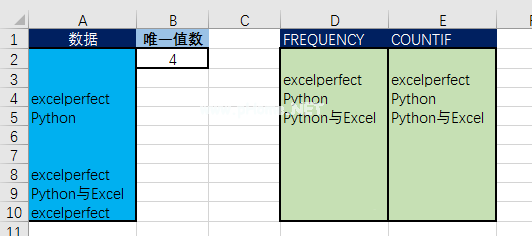
图3。
在B2单元格中,计算列表中返回的唯一值的数量:
=SUMPRODUCT((A2:A10 " ")/(COUNTIF(a 2: a10,a 2: a10 " "))
在d列中,使用FREQUENCY函数获取唯一值列表。在单元格D2中输入数组公式:
=IF(ROWS(1:1美元)$B$2,"",INDEX(A $ 2: A $ 10,SMALL(IF(FREQUENCY)(IF(A $ 2: A $ 10)",MATCH(A $ 2: A $ 10,A $ 2: A $ 10,0)),ROW(A $ 2: A $ 10,0)-MIN(ROW(A $ 2: A $ 10)),1
向下拉,直到出现一个空单元格。
在e列中,使用COUNTIF函数获取唯一值列表。在单元格E2中输入数组公式:
=IF(ROWS(1:1美元)$B$2 " ",INDEX(A $ 2: A $ 10,MATCH(0,IF(A $ 2: A $ 10 " ",COUNTIF(E$1:E1,$ A $ 2: A $ 10 " "),0)))
向下拉,直到出现一个空单元格。
(作者个人倾向于使用第一个公式,比COUNTIF版本更灵活,速度更快,特别是当从中获取唯一值的数组是公式中其他函数生成的数组时。COUNTIF函数的缺点是传递给它的参数必须是实际的工作表区域引用。)
从上面的例子可以看出,FREQUENCY函数可以处理单行或单列数组,但是我们这里生成的是10行4列的数组,那么FREQUENCY函数能处理这样的二维数组吗?不幸的是,答案是否定的。虽然INDEX、SMALL和FREQUENCY函数可以处理这样的数组,但MATCH函数不能,传递给它的lookup_array参数必须是单行或单列的。
因此,我们需要采用一种技术,将这里的数组转换为单行或单列数组。
(3)回到前面,定义名称Arry3的公式现在可以转换为:
INDEX({“苋菜”、“青铜”、“白银”、“;“青铜”、“”、“”、“”;"","","","";“紫罗兰”、“青铜”、“苋菜”、“;“红”、“”、“”、“”;“深褐色”、“青铜色”、“褐色”、“褐色”;“灰褐色”、“赭色”、“青铜色”、“瑟色”;“银色”、“红色”、“瑟色”、“橙色”;"","","","";“Cerise”、“”、“”、“}、N(IF(1,1 INT((Arry2-1)/MAX(Arry1))))、N(IF(1,1 MOD(Arry2-1,MAX(Arry1))))
如我们所见,INDEX的行和列参数有两种结构:
N(IF(1,1 INT((Arry2-1)/MAX(Arry1)))
和
N(IF(1,1 MOD(arr 2-1,MAX(arr 1)))
这里引用了Arry2这个名字:
行(间接(“1:”(最大值(arr y1)*行(数据)))
上面已经计算出Arry1的最大值为4,Data中的行数为10,因此上面的公式转换为:
行(间接(“1:”40))
因此,Arry2是由1到40:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}
这样,在上面的构造中:
1 INT((Arry2-1)/MAX(Arry1))
变成:
1 INT(({ 1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}-1)/4)
转换为:
1 INT({ 0;0.25;0.5;0.75;1;1.25;1.5;1.75;2;2.25;2.5;2.75;3;3.25;3.5;3.75;4;4.25;4.5;4.75;5;5.25;5.5;5.75;6;6.25;6.5;6.75;7;7.25;7.5;7.75;8;8.25;8.5;8.75;9;9.25;9.5;9.75})
转换为:
1 {0;0;0;0;1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9}
结果是:
{1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10}
同样,在列参数构造中:
1 MOD(arr 2-1,MAX(arr 1))
可转换为:
{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4}
由于这两个数组具有相同的向量位移(即都是单列数组),我们知道当传递给INDEX函数进行处理时,这些数组中对应的元素会“配对”,所以我们会指示INDEX返回一个值数组,其row_num和col_num参数依次为1/1、1/2、1/3、1/4和2。也就是说,我们将依次从上面生成的10行4列的数组中取值。
定义名称Arry3的公式现在可以转换为:
INDEX({“苋菜”、“青铜”、“白银”、“;“青铜”、“”、“”、“”;"","","","";“紫罗兰”、“青铜”、“苋菜”、“;“红”、“”、“”、“”;“深褐色”、“青铜色”、“褐色”、“褐色”;“灰褐色”、“赭色”、“青铜色”、“瑟色”;“银色”、“红色”、“瑟色”、“橙色”;"","","","";“Cerise”、“”、“”、“}、{ 1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10},{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4})
变成最后的结果:
{“苋菜”;“青铜”;“银”;"";“青铜”;"";"";"";"";"";"";"";《紫罗兰》;“青铜”;“苋菜”;"";“红色”;"";"";"";“Puce”;“青铜”;"";"";“灰褐色”;“赭石”;“青铜”;“Cerise”;“银”;“红色”;“Cerise”;“橙色”;"";"";"";"";“Cerise”;"";"";""}
到目前为止,10行4列的原始数组已经成功转换为40行1列的数组。这样,您可以将这个数组传递给MATCH函数,而不会出错。
注意,在上面的结构中,前面部分是N(IF(1),就是强制INDEX返回一个数组。详细原因见《Excel公式技巧03:INDEX函数,给公式提供数组》。
2.使用Arry3替换公式中使用FREQUENCY函数查找唯一值的单元格区域,并进行适当调整以获得单元格B2中的公式:
=IF(ROWS($1:1)$C$1,"",INDEX(Arry3,SMALL(IF(FREQUENCY)(IF(Arry3 " "),MATCH(Arry3,arry 3,0)),Arry2),Arry2),ROWS($1:1)))
3.关于计算C1单元中唯一值数量的公式:
=sum((Arry3 " ")/mmult(0(arr y3=转置(arr y3)),ROW(间接(“1:”counta(arry3)))^0))
(1)比较1)Arry3中的元素是否为空,得到一个数组:
{真;真;真;假;真;假;假;假;假;假;假;假;真;真;真;假;真;假;假;假;真;真;假;假;真;真;真;真;真;真;真;真;假;假;假;假;真;假;假;FALSE}
(2)看MMULT中的第二个数组:
行(间接(“1:”counta(arry3)))^0
我们已经知道Arry3中的元素个数是40,所以上面的数组是:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}^0
结果是:
{1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1}
(3)查看MMULT中的第一个数组:
0(Arry3=转置(arry 3))
这将被转换成一个40行40列的数组。由于数组太大,为了方便说明其原理,数据区数据简化为A1:A2,所以Arry3为:
{“苋菜”;“青铜”;“银”;“青铜”;"";""}
此时,MMULT中的第一个数组被转换为:
0 ({“苋菜”;“青铜”;“银”;“青铜”;"";" " }={“苋菜”、“青铜”、“银”、“青铜”、“文”、“文”})
比较两个正交表的结果是:
0 {真、假、假、假、假、假、假;假,真,假,真,假,假;假,假,真,假,假,假;假,真,假,真,假,假;假,假,假,假,真,真;假,假,假,假,真,真}
将0添加到1/0的数组中:
{1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1}
(4)此时,MMULT公式为:
MMULT({1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1},{1;1;1;1;1;1})
获取:
{1;2;1;2;2;2}
(5)此时,求和公式为:
=SUM({ TRUE;真;真;真;假;FALSE }/{ 1;2;1;2;2;2})
转换为:
=SUM({ 1;0.5;1;0.5;0;0})
结果是3。它表示如果数据区域是A1:A2,则有3个唯一值。
(6)回到示例中的数据区A1:A10,此时的SUM公式为:
=SUM({ TRUE;真;真;假;真;假;假;假;假;假;假;假;真;真;真;假;真;假;假;假;真;真;假;假;真;真;真;真;真;真;真;真;假;假;假;假;真;假;假;FALSE }/{ 2;5;2;21;5;21;21;21;21;21;21;21;1;5;2;21;2;21;21;21;1;5;21;21;1;1;5;3;2;2;3;1;21;21;21;21;3;21;21;21})
转换为:
=SUM({ 0.5;0.2;0.5;0;0.2;0;0;0;0;0;0;0;1;0.2;0.5;0;0.5;0;0;0;1;0.2;0;0;1;1;0.2;0.333333333333333;0.5;0.5;0.333333333333333;1;0;0;0;0;0.333333333333333;0;0;0})
结果是10。它表示数据区A1:A10中有10个唯一值。
总结
解决这种情况的过程是首先从由空格分隔的原始字符串生成一个子字符串数组,然后重新构建该数组,以便可以对其进行处理。至少我们可以从这个案例中学到:
1.使用大量的空格替换来拆分由分隔符分隔的字符串。
2.从列表中获取唯一值的标准公式。
3.将二维数组转换为一维数组的方法。
版权声明:excel公式技巧:从单元格区域的字符串中提取唯一值是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















