木偶师在实战中抓取动态生成的网页
木偶师的介绍和安装不太多,可以通过以下链接了解
第一,木偶师
开源地址
英文文件
华人社区
第二,抓取动态网页
1.需求
首先,了解我们的要求。在zoomcharts文档的Net Chart目录下抓取与所有访问连接相对应的页面,并将其保存在本地
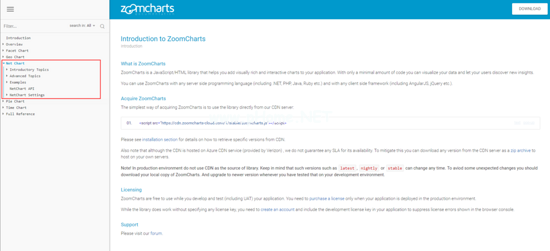
2.研究ZoomCharts文档的页面结构
首先,我们必须研究如何加载左导航的ZoomCharts页面和DOM树结构,然后才能进行下一步
第一次加载页面

第一次加载页面时,左侧导航中的第一个目录“简介”会突出显示。从控制台可以看到,这个元素中增加了活动类,li[data-section='net-chart']节点下只有一个元素节点A。
单击网络图表目录
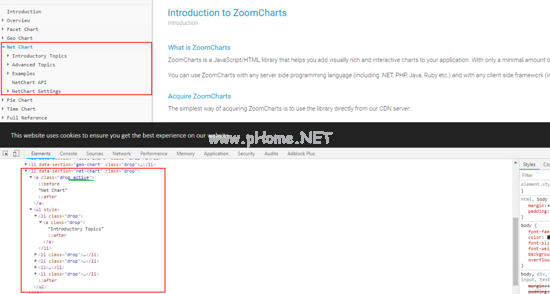
单击“网络图表目录”,突出显示“网络图表目录”,下拉并显示子目录,检查控制台,并将活动类和ul子元素节点添加到其元素节点。此时,第一个子目录节点只有一个子元素节点a。
结论
不难发现,左边的目录是动态生成的,不是静态写死的。只有单击父目录,才会生成并显示其子目录。同时,父目录元素上的drop类指示子目录的存在
3.编写主程序
通过以上分析,大致过程如下
从上到下遍历网络图目录的DOM树。找到a.drop的元素节点时,模拟鼠标点击事件,生成子目录节点,在Net Chart目录中找到所有a链接,生成数组,遍历数组,访问每个子目录页面,将页面的html文件保存在本地,然后实现每个具体的流程
项目初始化
安装木偶师rimraf(文件夹操作所需)
Npm i -S木偶师rimraf创建了一个新的test.js文件并介绍了它
const木偶师=require('木偶师');const粉笔=require('粉笔');const path=require(' path ');const https=require(' https ');const fs=require(' fs ');const RM=require(' rim RAF ');const settings={ headless : false }函数resolve(dir,dir 2=' '){ return path . POSIX . join(_ dir name,'。/',dir,dir 2);} async function main(){ const browser=wait puppeter . launch(设置);//创建一个Browser对象,尝试{ const page=await Browser . new page();//使用Browser创建page page . setdefaultnavigationtime out(600000);//收听consolepage.on ('console ',msg={for(让I=0;i msg.args()。长度;I){ console . log(` $ { I } : $ { msg . args()[I]} `);} });-主启动- //主区域!-endstart-console.log('服务正常结束')} catch(错误){console.log('服务有错误:')console.log(错误)}最后{}} main()接下来,所有代码都在main区域完成,完整的代码可以在github代码仓库中查看。下面只列出了每个部分的想法。
创建用于保存已爬网文件的文件夹
定义文件输出路径,并根据路径生成文件夹。当文件夹已经存在时,首先删除它,然后创建一个新的点击事件来实现网络图表目录中的所有拖放元素
这部分涉及到DOM操作。只有在page.evaluate()中才能访问真实的DOM元素。同时,外部定义的函数不能直接在page.evaluate()中调用,但可以传入或绑定到window对象。
wait page . evaluate(async()={ const rootNode=document . queryselector(' menu ul Li : th-child(5)ul Li : th-child(5)');wait window.walkDOM(rootNode)})此时,需要在页面中定义绑定到窗口对象的walkDOM函数,page.evaluateOnNewDocument函数才能生效
await page . evaluateconnectowdocument(()={//traverse DOM window . walk DOM=(Node)={ If(Node===null){ return } If(Node . tagname==' a ' Node . class name . indexof(' drop ')-1){ Node . click()//click event } Node=Node . first elementchildwhile(Node){ walk DOM(Node)Node=Node。nextelementsibling}})当单击“网络图表”目录中的所有. drop元素时,将加载并生成“网络图表”目录中的所有子代子目录,下一步操作很简单
获取网络图表目录中的所有元素
通过document.querySelectorAll()查找所有A元素,保存它们遍历数组,将数组的每一项处理成{href: ' ',text: ''}对象,返回对象数组,遍历对象数组,访问每个链接,下载其HTML文件。
跳转到每个链接,并下载所需的html到指定的文件夹。当HTML中有img时,下载所有图片。4.摘要
第一次用木偶师也很尴尬。这需要很多时间。期间也参考了很多文章,需要多加练习
代码仓库
代码仓库
以上就是本文的全部内容。希望对大家的学习有帮助,支持我们。
版权声明:木偶师在实战中抓取动态生成的网页是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















