通过node.jsjade抓取所有博客文章来生成静态html文件的示例
在本文中,我们整理了上一篇文章中收集的所有文章列表的信息,并开始收集文章和生成静态html文件。首先看我的收藏效果。我的博客目前有77篇文章,都是在不到1分钟的时间里收集生成的。这里我截了一些图片,文件名是由文章的id生成的。对于生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的。
项目结构:


好了,接下来,让我们解释一下本文的主要功能:
1、抓取文章,主要抓取标题、内容、超链接、文章id(用于生成静态html文件)
2.根据jade模板生成html文件
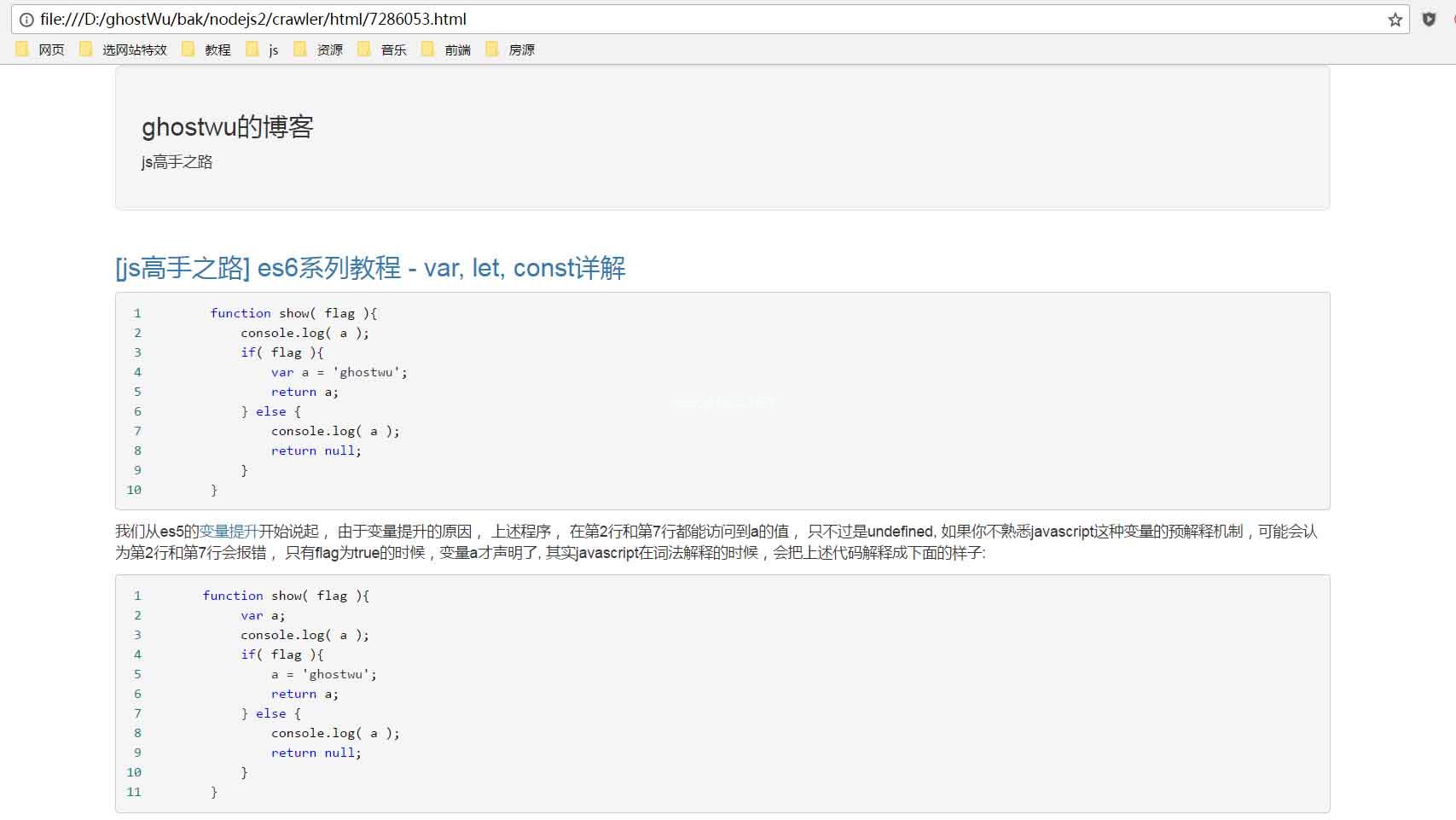
1.如何抓取文章?
它非常简单,类似于上面抓取文章列表的实现
函数crawlerArc(URL){ var html=' ';var str=var arcDetail={ };http.get(url,function (res) { res.on('data ',function(chunk){ html=chunk;});res.on('end ',function(){ arcDetail=filter article(html);str=jade.renderFile('。/view/layout . jade ',arc detail);fs.writeFile('。/html/' arcDetail['id']。html ',str,function(err){ if(err){ console . log(err);} console . log(' success : ' URL);if(AurL . length)crawler arc(AurL . shift());} );});});}参数url是文章的地址。抓取文章内容后,调用filterArticle(html)过滤出所需的文章信息(id、标题、超链接、内容),然后使用jade的renderFile api替换模板内容。
模板内容替换后,肯定要生成一个html文件,所以用writeFile写文件,写文件的时候用id作为html文件名。这是生成静态html文件的实现,
下一步是在循环中生成静态html文件,如下行:所示
if(AurL . length)crawler arc(AurL . shift());
AUrl保存了我博客中所有文章的Url。每次收藏一篇文章后,删除当前文章的url,让下一篇文章的URL出来,继续收藏
完整的实现代码server.js:
var fs=require(' fs ');var http=require(' http ');var cherio=require(' cherio ');var jade=require(' jade ');var ArtI=[];var AurL=[];函数过滤文章(html){ var $=cheerio。加载(html);var arcDetail={ };var title=$('#cb_post_title_url ').text();var href=$('#cb_post_title_url ').attr(' href ');var re=/\/(\d )\ .html/;var id=href。匹配(重新)[1];var body=$('#cnblogs_post_body ').html();返回{ id : id,title : title,href : href,body : body };}函数crawler arc(URL){ var html=' ';var str=var arcDetail={ };http.get(url,function (res) { res.on('data ',function(chunk){ html=chunk;});res.on('end ',function(){ arcDetail=filter article(html);str=jade.renderFile(' ./视图/布局。‘玉’,弧形细节);fs.writeFile(' ./html/' arcDetail['id'].html ',字符串,函数(err){ if(err){ console。日志(err);}控制台。日志('成功: ' URL);if(AurL。长度)履带弧(AurL。shift());} );});});}函数FilterHTML(html){ var $=cheerio。加载(html);var arcList=[];var aPost=$('#content ').查找('。后列表项目');阿波斯特。每个(function(){ var ele=$(this);var title=ele.find('h2 a ').text();var url=ele.find('h2 a ').attr(' href ');ele.find ' .c _ b _ p _ desc a’.移除();var entry=ele.find ' .c_b_p_desc ' .text();ele.find('小a ').移除();var listTime=ele.find('small ').text();var re=/\ d { 4 }-\ d { 2 }-\ d { 2 } \ s * \ d { 2 }[:]\ d { 2 }/;列表时间=列表时间。match(re)[0];arcList.push({ title: title,url: url,entry: entry,listimes : listimes });});返回arcList}函数NextPage(html){ var $=cheerio。加载(html);var NextURl=$(' # pager a : last-child ').attr(' href ');if(!nextUrl)返回GetArcurl(ArtI);var CurPage=$(' #寻呼机.当前')。text();if(!cur page)cur page=1;var下一页=下一个网址。子字符串(下一个网址。indexof('=')1);if (curPage下一页)爬虫(下一个网址);}函数crawler(url) { http.get(url,function(RES){ var html=' ';res.on('data ',function(chunk){ html=chunk;});res.on('end ',function(){ ArtI。push(FilterHTML(html));下一页(html);});});}函数getArcUrl(arcList){ for(arcList中的定义变量键){ for(arcList[key]中的var k)} { aurl。推送(arcList[key][k][' URL ']);} } crawler arc(AuRL。shift());} var URL='http://www.cnblogs.com/ghostwu/';爬虫(网址);布局。翡翠文件:
doctype html html head meta(charset=' utf-8 ')title jade节点。js快速链接(rel='样式表,href=' ./CSS/bower _ components/bootstrap/dist/CSS/bootstrap。量滴' CSS ')正文块标题div。集装箱处。好吧。嗯——LG鬼吴的博客p js高手之路阻止容器分区。容器H3 a(href=' # { href } ' rel='外部无跟随')!{title} p!{body}块页脚div。容器页脚版权所有-由幽灵后续的打算:
1,采用mongodb入库
2,支持断点采集
3,采集图片
4,采集小说
等等.
以上这篇Node.js jade抓取博客所有文章生成静态超文本标记语言文件的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
版权声明:通过node.jsjade抓取所有博客文章来生成静态html文件的示例是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















