每秒50万字!Js实现关键词匹配
在论坛、聊天室这样的场景中,为了保证用户体验,我们往往需要屏蔽很多不良词汇。对于单关键词搜索,indexOf,正则自然更有效率。但是当关键词较多时,如果重复调用indexOf和正则来匹配全文,性能消耗非常大。由于目标字符串通常很大,因此有必要确保在一次遍历后就能获得结果。根据这个需求,很容易想到依次匹配全文中每个字符的方法。例如,对于这段文字:“迈克乔丹说过‘照做就是了’,所以马克一直是个编码员。”如果我们的关键词是“Mike”和“mark”,我们可以遍历整个句子,那么当我们找到“M”的时候,我们可以看看我们是否可以匹配“I”或“A”,我们可以成功地找到一个关键词,直到结束,否则我们可以继续遍历。那么关键词的结构应该是这样的:
Var关键字={ m : { I : { k : { e : { end : true } },a : { r : { k : { end : true } } }从上面可以看出,这个数据是一个树形结构,是根据关键字组创建的代码如下:
函数buildTree(关键字){ var tblCur={},key,str_key,Length,j,I;var tblRoot=tblCurfor(j=关键字. length-1;j=0;j -=1) { str_key=关键字[j];Length=str _ key.lengthfor(I=0;一.长度;I=1){ key=str _ key . charat(I);if(tblCur . hasown property(key)){ tblCur=tblCur[key];} else { TbLCur=TbLCur[key]={ };} } tblCur.end=true//最后一个关键字tblCur=tblRoot}返回tblRoot}此代码使用了一个等式语句:tblCur=tblCur[key]={}。这里要注意语句的执行顺序。因为[]的操作级别比高于=,所以首先在tblCur对象中创建一个键属性。结合tblRoot=tblCur={},执行顺序为:
var tblRoot=tblCur={ };tblRoot=tblCurtblCur['key']=未定义;//现在tblRoot={ key : undefined } tblCur[' key ']={ };tblCur=tblCur[' key '];所需的查询数据由上述代码构造。让我们看一下查询接口的编写。
对于目标字符串中的每个单词,我们从这个关键字的顶部开始匹配。一、关键词[a],如果有,看关键词[a] [b]。如果关键字[a][b] … [x]=true,则表示匹配成功。如果关键字[a][b]…[x]=undefined,它将从下一个位置开始再次匹配关键字[a]。
函数search (content) {var tblcur,p _ star=0,n=content.length,p _ end,match,//是否找到match _ key,match _ str,arr match=[],//存储结果arrLength=0;//的长度索引//arrMatch while(p _ star n){ tblCur=tblRoot;//回到根p _ end=p _ starmatch _ str=match=falsedo { match _ key=content . charat(p _ end);if(!(tblcur=tblcur [match _ key])本次比赛结束时{//p _ star=1;打破;} else { match _ str=match _ key} p _ end=1;If(tblCur.end) //匹配到尾部{ match=true} } while(true);If(match) {//最大匹配arr match[arr length]={ key : match _ str,begin:p _ star-1,end : p _ end };arrLength=1;p _ star=p _ end} }返回arrMatch}以上是整个关键词匹配系统的核心。这里很好的利用了js的语言特性,效率很高。我用了一个50万字的《搜神记》作为测试,从中发现了300个成语,匹配效果大概1秒。重要的是,因为目标文本被遍历一次,所以目标文本的长度对查询时间几乎没有影响。关键词的数量对查询时间影响很大,目标文本的每个词都会遍历一次关键词,因此对查询有一定的影响。
简单分析
看到上面,你可能会想,遍历每个单词的所有关键词,即使有些关键词部分相同,完全遍历也是相当耗时的。然而,js中对象的属性是使用哈希表构造的。这种结构的数据与简单的数组遍历有很大不同,其效率远高于基于序列的数组遍历。有些学生可能不熟悉数据结构。在这里,我将简单谈谈哈希表的内容。
首先看数据的存储。
数据在内存中的存储由两部分组成,一部分是值,另一部分是地址。把记忆当成新华字典。这个词的解释是价值,目录是地址。字典是按拼音排序的,例如,发音相同的“ni”排列在同一个块中,也就是说,数组整齐地排列在一个存储区中。这个结构是一个数组,你可以指定“Ni”1号和10号来访问它。结构图如下:

数组的优点是容易遍历,对应的数据可以通过下标直接访问。但是添加或删除一个项目是非常困难的。例如,如果要删除第6项,则第5项后的数据应向前移动一个位置。如果要删除第一位,就要移动整个数组,成本非常高。

为了解决数组的增删问题,链表出现了。如果我们把值分成两部分,一部分用来存储原始值,另一部分用来存储一个地址,这个地址指向另一个相同的结构,以此类推,就形成了一个链表。结构如下:

从上图可以清楚地看到,添加或删除链表非常简单,只要重写目标项和上一项的下一个即可。但是,查询一个项目的值是非常困难的,您必须依次遍历它,然后才能访问目标位置。
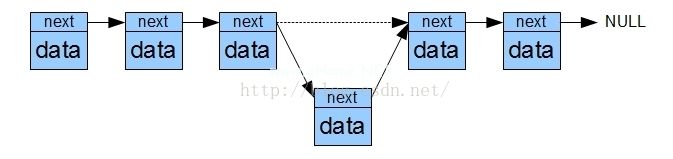
为了综合这两种结构的优点,你一定想到了下面的结构。

这种数据结构是哈希表结构。通过将链表的首地址存储在数组中,可以形成二维数据表。至于数据如何分配,这是哈希算法,形式翻译应该是哈希算法。算法虽然有很多种,但原则上是用一个函数来求解密钥,然后根据求解的结果来放置数据。也就是说,在键和实际地址之间形成了一个映射,所以此时我们不再用数组下标或者简单遍历来访问数组,而是用hash函数的反函数来定位数据。js中的对象是一个散列结构。例如,如果我们定义了一个obj,而obj.name通过了散列,那么在上面的图中,它在内存中的位置可能是90。当我们想要操作obj.name的时候,底层会通过哈希算法自动帮助我们定位90的位置,也就是说我们可以直接从数组的12项开始搜索链表,而不是从0开始遍历整个内存块。
js中定义了一个对象obj{key: value}。密钥被转换成一个字符串,然后被散列得到一个内存地址,然后值被放入其中。这可以理解为什么我们可以随意添加或删除属性,为什么我们可以在js中为数组分配属性,并且数组没有所谓的越界。
哈希表在数据量较大时具有明显的优势,因为它通过哈希算法减少了许多不必要的计算。所谓性能优化,其实就是让电脑少操作;最大的优化就是不算!
算法优化
既然我们了解了算法的底层实现,我们可以考虑优化算法。但是,在优化之前,我们要强调一点:不要盲目追求性能!比如在这种情况下,我们最多可以匹配5000个单词,那么现有的算法就足够了,所有的优化都是不必要的。我们谈论优化的原因是为了提高我们对算法和程序的理解,而不是真正做1毫秒的优化。
我们发现我们的关键词都没有一个词,所以我们按照一个词的单位去遍历关键词显然是浪费。这里的优化是预先统计关键词的最大长度和最小长度,每次以最小长度为单位进行搜索。比如我的测试用例的关键词是成语,最短的是4个字,所以每次匹配的时候,我都是4个字一起匹配。如果我击中它,我会继续搜索最大长度。也就是说,我们第一次构造树的时候,先用最小长度构造,然后一个字一个字地增加。
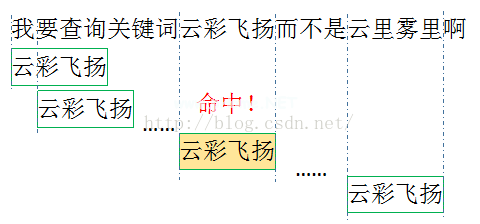
简单算一下,根据我们的测试用例,300个成语,我们匹配一个词只需要比较一次,查询单个词需要比较四次,每次比较都需要访问我们的树形结构,这是可以避免的性能消耗。更重要的是,这里的比较不是字符串比较。我们的关键字是作为关键字存在的,效果和obj中的关键字一样,就是把关键字散列后再访问对应的地址!所以不要纠结比较一个词和比较四个词的区别。我们没有比较字符串!
以上就是多关键词匹配的全部内容。优化后的代码我就不贴了,因为一般不会用。
版权声明:每秒50万字!Js实现关键词匹配是由宝哥软件园云端程序自动收集整理而来。如果本文侵犯了你的权益,请联系本站底部QQ或者邮箱删除。
















